Table of Contents >> Show >> Hide
- What Is TCP Congestion Control?
- Why Congestion Happens in the First Place
- The Classic Four: TCP’s Foundational Congestion Control Behaviors
- How TCP Knows It Should Slow Down
- A Simple Mental Model: AIMD
- Popular TCP Congestion Control Algorithms You Will Hear About
- A Real-World Example Without the Math Headache
- Why TCP Congestion Control Matters for SEO, Web Performance, and User Experience
- Common Misconceptions
- Practical Experiences With TCP Congestion Control in the Wild
- Final Thoughts
TCP congestion control is one of those invisible technologies that quietly keeps the internet from behaving like a freeway at rush hour after someone dropped a ladder. Most people never think about it. They click, stream, upload, refresh, and expect everything to work. Behind the scenes, though, TCP is constantly making judgment calls about how fast it should send data, when it should slow down, and how to recover when the network starts acting like it had too much coffee.
If you have ever wondered why one download starts blazing fast and then chills out, why latency sometimes spikes when a link gets busy, or why networking people get weirdly excited about words like CUBIC, BBR, and ECN, you are in the right place. This guide gives you a practical introduction to TCP congestion control without making you feel like you accidentally opened a graduate textbook.
We will cover what congestion control is, why TCP needs it, the classic algorithms that built the modern internet, the newer approaches that try to do better, and what all of this means in real life for websites, servers, apps, and everyday users.
What Is TCP Congestion Control?
TCP congestion control is the set of rules a TCP sender uses to decide how much unacknowledged data it can have in flight at one time. The goal is simple in theory and delightfully messy in practice: send enough data to make efficient use of the network, but not so much that queues overflow, packets drop, delay explodes, and everything turns into digital soup.
TCP does not get a magical dashboard showing every router, queue, and bottleneck between sender and receiver. Instead, it infers the state of the network from signals such as acknowledgments, packet loss, round-trip time, and sometimes Explicit Congestion Notification, or ECN. Based on those hints, it adjusts its congestion window, often shortened to cwnd. That window is basically TCP’s way of saying, “I think I can safely have this much data in transit without causing trouble.”
Think of congestion control as a polite but slightly paranoid driver. It accelerates when the road looks clear, taps the brakes when traffic thickens, and becomes dramatically cautious after a close call.
Why Congestion Happens in the First Place
Networks have limited capacity. If multiple senders push more traffic through a path than the bottleneck link or queue can handle, packets start piling up. At first, that creates queueing delay. If the queue keeps filling, packets get dropped. Once drops happen, senders retransmit, which can make congestion worse if they keep sending aggressively. Congratulations: you now have the networking equivalent of a parking lot where everyone is simultaneously honking and trying to reverse.
TCP was designed to avoid that disaster spiral. A healthy congestion control algorithm tries to balance three competing goals:
1. High throughput
Use as much available bandwidth as possible so data moves quickly.
2. Low latency
Avoid building giant queues that make everything feel slow and sticky.
3. Fairness
Share bottleneck capacity reasonably with other flows instead of behaving like the networking version of someone taking all the pizza slices “for later.”
The Classic Four: TCP’s Foundational Congestion Control Behaviors
Traditional TCP congestion control is often introduced through four core mechanisms: slow start, congestion avoidance, fast retransmit, and fast recovery. These are the classics. They are not trendy, but they are the reason the internet did not melt down decades ago.
Slow Start
Despite the name, slow start is actually pretty enthusiastic. TCP begins cautiously because it has no idea how much capacity is available. Then, as acknowledgments return, it increases the congestion window rapidly, often doubling roughly once per round-trip time. This exponential growth helps a new connection discover usable bandwidth quickly.
Why not just start at full speed? Because “full speed” is not a number TCP knows in advance. A new flow could be crossing a sleepy local network or a crowded long-haul path shared with a thousand other conversations. Slow start is TCP’s way of probing the network without immediately body-slamming it.
Congestion Avoidance
Once TCP reaches a threshold where caution feels wise, it shifts into congestion avoidance. Instead of growing the congestion window explosively, it increases more gently, commonly using the famous additive increase pattern. This slower growth gives the sender a chance to approach the network’s true capacity without overshooting too hard.
In plain English, slow start says, “Let’s accelerate and see what happens.” Congestion avoidance says, “Okay, maybe now let’s stop pretending we are invincible.”
Fast Retransmit
When packets arrive out of order, the receiver can send duplicate ACKs for the last in-order segment it received. If the sender sees enough duplicate ACKs, it assumes a packet was lost and retransmits it right away instead of waiting for a long timeout. That is fast retransmit, and it is a major quality-of-life upgrade for TCP.
Fast Recovery
After detecting loss via duplicate ACKs, TCP usually reduces its sending rate, but it does not always slam on the brakes all the way back to the beginning. Fast recovery helps the sender recover more gracefully, keeping data flowing while still reacting to congestion. It is basically the protocol equivalent of stumbling, regaining balance, and continuing the run instead of lying on the sidewalk rethinking your life choices.
How TCP Knows It Should Slow Down
TCP is a detective, not a mind reader. It uses indirect evidence to guess whether the network is congested.
Packet loss
Traditional loss-based TCP interprets packet loss as a strong sign of congestion. If packets vanish, the sender assumes a queue overflowed somewhere and reduces its sending rate.
Round-trip time (RTT)
If RTT rises, that can mean packets are spending more time waiting in queues. Delay is not always caused by congestion, but it is often a useful clue.
Acknowledgment behavior
The pattern and timing of ACKs tell the sender how quickly data is leaving the network and reaching the receiver.
ECN markings
With Explicit Congestion Notification, network devices can mark packets instead of dropping them to warn endpoints that congestion is building. That allows TCP to react before loss occurs, which is much nicer for latency-sensitive traffic. It is like getting a polite warning from traffic lights instead of discovering the problem by crashing into a jam.
A Simple Mental Model: AIMD
A lot of classic TCP behavior can be summarized by one famous idea: Additive Increase, Multiplicative Decrease, usually called AIMD.
Under AIMD, TCP increases its congestion window gradually when things look good, then cuts the window more sharply when congestion appears. This pattern helps flows converge toward a fair share of bandwidth while still using the link efficiently.
Imagine two TCP flows sharing a bottleneck. If both cautiously increase over time, they inch toward full utilization. When congestion hits, both back off. Repeat that cycle enough times and they tend to settle into a rough balance. Not perfect balance, because real networks are chaotic little goblins, but good enough to be hugely useful.
Popular TCP Congestion Control Algorithms You Will Hear About
Reno and NewReno
Reno-style congestion control is the old-school reference point. It is closely associated with the classic slow start, AIMD-style congestion avoidance, fast retransmit, and fast recovery model. NewReno improves recovery behavior when multiple losses happen in one window. If you want the “intro course” version of TCP congestion control, Reno and NewReno are usually where the lecture begins.
CUBIC
CUBIC was designed to perform better on fast, high-bandwidth, long-distance networks where traditional linear growth can feel painfully conservative. Instead of increasing cwnd in a purely linear way, CUBIC uses a cubic growth function based on time since the last congestion event. That lets it scale better on modern links while still backing off when congestion appears.
CUBIC matters because it became the default congestion control algorithm in major operating systems and server environments. In practical terms, that means a huge portion of real-world TCP traffic has been shaped by CUBIC’s behavior for years.
BBR
BBR, short for Bottleneck Bandwidth and Round-trip propagation time, takes a different approach. Instead of relying primarily on packet loss as the signal that the network is too full, BBR tries to model the path by estimating the bottleneck bandwidth and the minimum RTT. Then it paces traffic based on that model.
The big promise of BBR is that it can achieve high throughput with lower latency than traditional loss-based algorithms, especially on paths where loss is not a reliable sign of persistent congestion. That is why BBR gets so much attention in discussions about modern transport performance. It also gets plenty of debate, because every new congestion control algorithm eventually meets the internet, and the internet always has opinions.
Vegas and delay-based ideas
Some algorithms, such as TCP Vegas, try to detect congestion earlier by watching delay rather than waiting for losses. Delay-based control can keep queues shorter and latency lower, but it can also be tricky when competing against more aggressive loss-based flows. In mixed environments, “being polite” does not always win the bandwidth contest.
DCTCP and specialized environments
Data Center TCP, or DCTCP, is designed for controlled environments such as data centers, where ECN support and relatively predictable conditions make more refined signaling practical. It is a great example of how congestion control is not one-size-fits-all. A strategy that shines in a data center may not behave the same way on the messy, public internet.
A Real-World Example Without the Math Headache
Suppose a server starts sending a large file to a user over a path with decent bandwidth but a mildly congested bottleneck router. At first, the TCP sender begins with a modest congestion window. ACKs come back quickly, so the sender ramps up. During slow start, it grows fast and reaches a much higher sending rate.
Then the bottleneck queue begins to fill. RTT creeps upward. If the algorithm is loss-based and no ECN is available, the sender may keep increasing until a packet drop occurs. At that point, it treats the loss as congestion, cuts its sending window, and enters recovery. Over time, it increases again and repeats the pattern.
If the sender uses a model-based approach like BBR, it may instead try to estimate the bottleneck bandwidth and minimum RTT, pace traffic accordingly, and avoid building a giant queue in the first place. The result can be better throughput-latency balance, though actual performance still depends on the path, competing traffic, and implementation details.
This is why congestion control is not just a theory problem. It directly affects page load times, video stability, bulk transfer speed, and the difference between “snappy” and “why is my app thinking so hard?”
Why TCP Congestion Control Matters for SEO, Web Performance, and User Experience
TCP congestion control may sound like something only kernel developers and networking engineers discuss at alarming length, but it absolutely affects normal websites and apps.
For web performance, congestion control influences how quickly assets can be delivered, how connections behave on mobile networks, and how gracefully traffic responds to competition and loss. A site can have optimized images, clean code, and excellent caching, but if transport behavior is poor under real network conditions, users still feel the drag.
That matters for user experience, engagement, and business metrics. Faster, smoother delivery helps reduce frustration. Lower latency makes interactive experiences feel more responsive. Better fairness can keep one noisy transfer from degrading everything else on a shared path.
In other words, congestion control is not just a network plumbing detail. It is part of the user experience stack, even if it lives below the part of the stack most marketers ever see.
Common Misconceptions
“More speed is always better.”
Not if “more speed” means stuffing queues until latency explodes. A smart sender aims for efficient delivery, not maximum chaos.
“Packet loss always means a bad network.”
Not necessarily. Loss can be a congestion signal, a wireless artifact, or something else entirely. That is one reason newer approaches try to look beyond loss alone.
“One congestion control algorithm is best everywhere.”
Also no. Different algorithms make different tradeoffs. The best choice depends on the path, the traffic pattern, the operating system, and the performance goals.
“TCP congestion control is obsolete because HTTP/3 and QUIC exist.”
QUIC has its own congestion control machinery, but it borrows many ideas from TCP’s long history. TCP did not retire to a beach house. It remains foundational, and its lessons still shape modern transport design.
Practical Experiences With TCP Congestion Control in the Wild
One of the most useful ways to understand TCP congestion control is to stop thinking about it as a paragraph in a standard and start thinking about how it feels during real troubleshooting. In practice, you rarely meet congestion control in a neat diagram. You meet it when a file transfer is mysteriously slow, when a video call becomes laggy during an upload, or when a server looks healthy on paper but users still complain that the site feels sluggish.
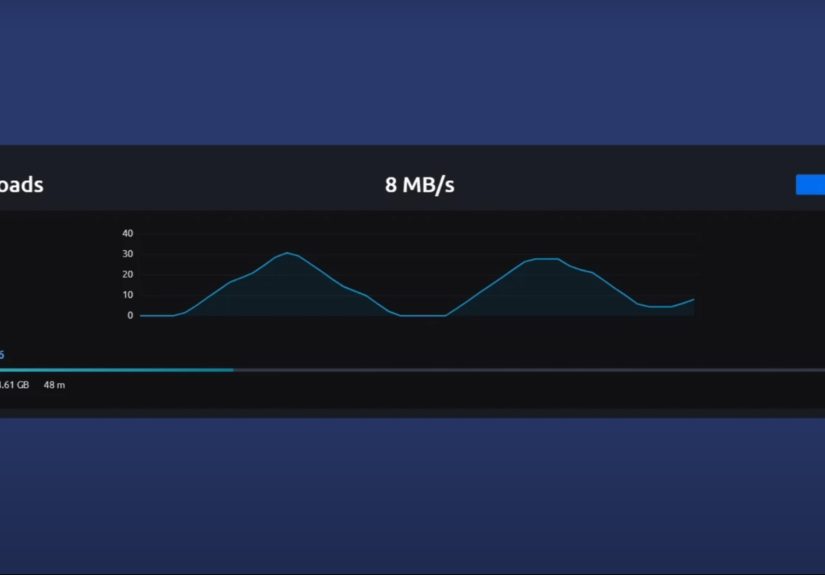
A common first experience happens during bandwidth testing. Someone sees a 1 Gbps link and assumes transfers should immediately sprint at full speed. Then the transfer starts, the rate climbs, dips, climbs again, and refuses to behave like a perfectly flat line. That is often congestion control doing its job. TCP is not trying to be dramatic. It is probing, learning, backing off, and adapting to the path in front of it.
Another memorable scenario shows up on high-latency paths. A connection across a continent, or through a satellite or mobile environment, can feel strangely hesitant at first. You realize that RTT matters a lot because each round-trip influences how quickly the sender can grow the congestion window. Suddenly, terms like bandwidth-delay product stop sounding academic and start sounding like the reason your transfer is taking forever to get up to speed.
Many engineers also encounter congestion control during bufferbloat investigations. On paper, the network is not dropping many packets, so everything appears “fine.” In reality, queues are bloated, latency is ugly, and users experience sticky performance. This is where you learn that maximizing throughput without controlling queues can create a terrible interactive experience. A network can look busy and technically functional while still feeling awful to humans.
There is also the eye-opening moment when two flows compete and behave differently. Maybe one system uses a more modern algorithm and another uses a more conservative one. Maybe one path has ECN support and the other does not. Maybe a wireless link introduces loss that is not purely caused by congestion. You start to see that TCP congestion control is less like a single rulebook and more like a set of strategies responding to imperfect evidence.
Perhaps the biggest practical lesson is humility. Congestion control is not magic, and it is not fixed forever. It is a continuously evolving attempt to make shared networks efficient, stable, and fair under wildly different conditions. When it works well, nobody notices. When it works badly, everyone notices, usually in all caps. That alone makes it worth understanding.
Final Thoughts
A quick introduction to TCP congestion control turns out to include some big ideas: fairness, efficiency, latency, loss recovery, and the art of making decisions with incomplete information. TCP has spent decades refining how senders behave on crowded networks, and that work remains deeply relevant today.
The classic mechanisms of slow start, congestion avoidance, fast retransmit, and fast recovery still define the foundation. Modern algorithms such as CUBIC and BBR build on that foundation in different ways, each trying to improve performance for modern links and workloads. Meanwhile, tools like ECN remind us that better signaling can help us avoid turning congestion into outright packet loss.
If you remember just one thing, make it this: TCP congestion control is the reason the internet can be shared by billions of connections without collapsing into a global buffering icon. It is not perfect, but it is one of the quiet engineering miracles that makes everyday computing feel normal. And frankly, “normal” is a pretty impressive outcome for something this complicated.