Table of Contents >> Show >> Hide
- Why Chess Turns Chatbots Into Chaos Goblins
- Base Models vs. Instruct Models: Same Foundation, Different “Personality Settings”
- The Instruct Model Mystery: Why Better Conversation Doesn’t Mean Better Chess
- Chess as a Stress Test for Long-Horizon Reasoning
- Specific Examples: How LLM Chess Breaks in Real Life
- How to Play Chess Against an LLM Without Losing Your Sanity
- What This Teaches Us About Instruct Models (Beyond Chess)
- Where the Field Is Heading: Making LLM Chess Less Weird
- Conclusion: The Real Endgame
- Experiences: A 500-Word Field Guide to Playing Chess vs. LLMs
Playing chess against a large language model (LLM) is a little like playing a friendly neighbor who’s
read every chess book ever written… but keeps forgetting where the pieces are. One moment the model
is confidently narrating a “solid Italian setup,” the next it’s suggesting a move that would get you
escorted out of a tournament by a very patient arbiter. And thenbecause it’s politeit apologizes,
compliments your “tactical prowess,” and proposes another illegal move with the energy of a golden
retriever presenting a stick.
That mix of surprising competence and sudden chaos is exactly why chess is such a revealing playground
for modern AI. Chess is unforgiving: rules are crisp, state matters, and “close enough” is the same as
wrong. Meanwhile, instruct models (the chatty, helpful versions of base LLMs) are optimized to follow
instructions and satisfy usersnot to keep a perfect internal ledger of reality. Put those together and
you get a genuine mystery: why do models that can write essays, code, and explanations still blunder at
a board game with only 64 squares?
Let’s unpack what’s really happening when you’re playing chess against LLMs, what “instruct models”
are (and why they behave the way they do), and how to set up chess interactions that feel less like
improv comedy and more like actual chess.
Why Chess Turns Chatbots Into Chaos Goblins
1) Chess is a rules engine disguised as a conversation
At face value, chess looks like language: “Nf3,” “Bishop takes,” “castle kingside.” But under the hood,
it’s a strict rules system with a continuously changing state. A move isn’t “good” because it sounds
plausibleit’s good only if it’s legal in the current position and improves your chances of winning.
LLMs, however, are trained to predict the next most likely text given the text so far. They’re excellent
at producing chess-y looking output (opening names, tactical motifs, common move patterns), but legality
requires exact state tracking: which pieces exist, where they are, whose turn it is, and what moves are
allowed right now.
2) State tracking is the real boss fight
Humans hold a mental model of the board. Chess engines store a literal board representation. Many LLM
chess experiences rely on the model to “remember” the board from a transcript of moves. That’s a fragile
setup, especially over long games, because the model is juggling:
- the move history (which grows every turn),
- piece locations (which must stay consistent),
- and conversational framing (“explain your plan,” “be concise,” “don’t use jargon”).
When that juggling act breaks, the failure is obvious: illegal moves, phantom captures, or pieces
teleporting like they just unlocked fast travel.
3) “Looks right” is not the same as “is right”
A classic LLM chess failure mode is producing a move that is common in similar-looking positions, but
impossible in the current one. For example, the model might recommend a knight jump that would be legal
if the knight were on a different squareor if a blocking piece didn’t exist. From the model’s perspective,
it’s generating a statistically plausible continuation; from chess’s perspective, it’s suggesting you
move a rook diagonally and then acting surprised when you don’t applaud.
Base Models vs. Instruct Models: Same Foundation, Different “Personality Settings”
To understand the “mystery” part, it helps to separate two families of models you’ll see discussed:
base models and instruct models.
Base model: the raw next-token predictor
A base model is trained on huge corpora of text to predict the next token. It’s the “foundation” that
learns language patterns, facts (sometimes), and correlations. If you prompt a base model directly, it
may be less polite, less structured, and less aligned with what you wantbut it may also be less eager
to “perform helpfulness” when it’s unsure.
Instruct model: the assistant that tries to do what you mean
An instruct model starts from a base model and is further tuned to follow instructions and produce more
helpful, safer, more user-aligned outputs. This typically involves:
- Instruction tuning / supervised fine-tuning (SFT): training on prompt–response pairs that look like good assistant behavior.
- Preference optimization (often via RLHF): using human feedback to push the model toward responses people prefer.
The result is a model that’s easier to use in everyday life. Ask for a summary, you get a summary. Ask
for a checklist, you get a checklist. Ask for a dad joke, you get a dad joke. (Ask for a legal chess move…
you often get a chess-sounding move.)
The Instruct Model Mystery: Why Better Conversation Doesn’t Mean Better Chess
Here’s the core paradox: instruct models are optimized to be helpful and responsive to your request,
but chess demands correctness under constraints. In normal conversation, if you say something slightly
ambiguous, a friendly assistant can make a reasonable guess and keep things moving. In chess, a “reasonable
guess” that’s illegal is just… illegal.
Helpful behavior can reward confident mistakes
Instruct tuning and RLHF-style training often reward outputs that humans rate as good: clear, confident,
well-structured, and aligned with the prompt. But in chess, the best answer is sometimes:
- “I can’t determine legality without the full position (FEN).”
- “Please confirm whether the knight is pinned.”
- “I need to check the board state before recommending a move.”
Those are honest responses, but they can feel less “helpful” to a user who just wants a move now.
So the model may learn a vibe: “always give an answer,” even when uncertainty is high.
Instruction-following adds another constraint layer
When you play chess with an LLM, you often add rules like:
“Only respond with SAN,” “Explain your reasoning,” “Don’t mention engines,” “Keep it short,” “Stay in character,”
and so on. That’s a lot of instructions, and they can compete with the harder, hidden instruction:
don’t break chess.
Chess is the ultimate pop quiz for instruction-following because it reveals whether the model prioritizes
surface-level formatting (“I output SAN!”) over underlying validity (“…but that move can’t happen.”).
Chess as a Stress Test for Long-Horizon Reasoning
Researchers and builders increasingly treat chess as a structured way to test LLM behavior over extended,
multi-step interactions. It’s not just “can it pick a good move?” It’s “can it stay coherent, follow a protocol,
and keep the game state consistent over time?”
What modern LLM chess benchmarks look for
A realistic evaluation doesn’t only track win/loss. It measures things like:
- Move legality: how often the model proposes illegal moves.
- Action formatting: whether the model follows the required output format (e.g., UCI, SAN, JSON actions).
- State consistency: whether it “forgets” earlier captures or piece locations.
- Long-horizon stability: whether performance degrades after 10, 20, 40 moves.
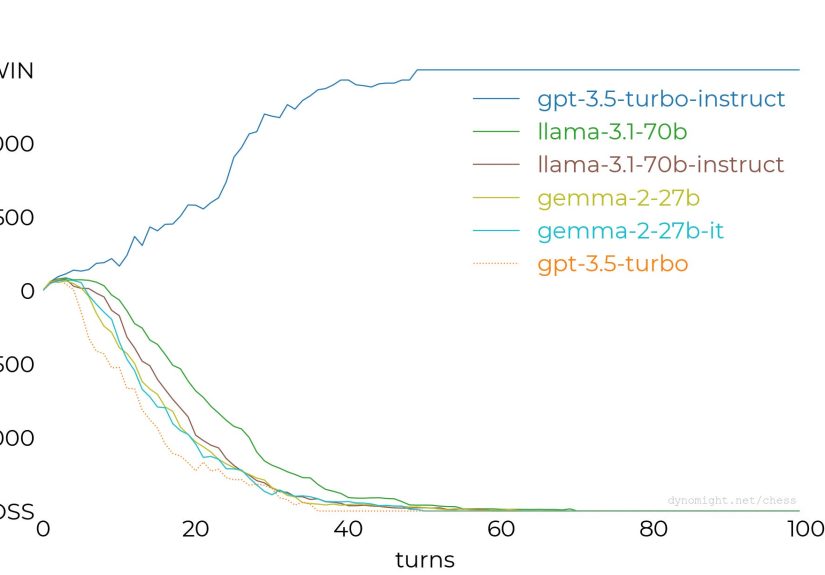
Why Magnus Carlsen vs. “chat chess” isn’t the point
Viral matchupslike a world champion dismantling a chatbotare entertaining, but they mostly show that chat
models aren’t chess engines. (No shock there.) The deeper takeaway is that chess reveals the gap between:
- language fluency (talking about chess), and
- formal competence (playing chess under rules).
You can explain the concept of a pin without being able to track the pinned piece on a real board. Chess makes
that difference painfully visible.
Specific Examples: How LLM Chess Breaks in Real Life
Example A: The “illegal move as advice” moment
A common experience: you ask, “What’s the best move here?” and the model confidently suggests something that
isn’t legallike recommending a knight jump to a square it can’t reach, or proposing a capture through a piece.
The move sounds right in isolation because it resembles patterns seen in similar positions.
Example B: The “I captured that pawn three turns ago” argument
Midgame, you might notice the model referencing a piece that’s already been traded off. You correct it. The model
apologizes. Then it continues as if the correction never happened. This isn’t stubbornness; it’s a sign the model’s
internal state is not a single persistent “board,” but a probability-weighted continuation of text.
Example C: Format obedience with content failure
You demand: “Only respond with UCI like e2e4.” The model complies perfectlywhile still outputting moves that are
illegal in the current position. This is the instruct model dilemma in miniature: it’s doing what you asked (format),
but not what you actually needed (legality).
How to Play Chess Against an LLM Without Losing Your Sanity
If you want the fun of LLM chess without the constant rules-lawyering, you need to structure the interaction so the
model isn’t forced to be both “board memory” and “move generator.”
Option 1: Use the LLM as a coach, not the move source
The best use of an instruct model is often explanation:
- Ask it to explain plans (“What are White’s candidate plans in this pawn structure?”)
- Ask for human-style heuristics (“What would a strong player look for here?”)
- Ask for post-move commentary (“Why is that blunder a blunder?”)
Let a chess engine (or your own play) handle legality. Let the LLM handle teaching, storytelling, and “why.”
Option 2: Always provide the full position (FEN) every turn
If you want the model to suggest moves, reduce memory load by giving it the current board state explicitly with FEN.
Then ask for 3 candidate moves and an explanation. A solid prompt looks like this:
This doesn’t guarantee perfection, but it dramatically reduces the “where are the pieces?” failure mode.
Option 3: Tool-augmented chess (LLM + engine)
The most reliable setup is a division of labor:
- Engine checks legality and evaluates candidate moves.
- LLM chooses from legal candidates and explains the plan in human terms.
In other words: let Stockfish do math; let the instruct model do communication. This also makes the instruct model
shine, because it’s now optimizing a task it’s great at: explaining and guiding.
Option 4: Hard constraints + automatic verification
If you’re building an app, don’t rely on “please only output legal moves.” Instead:
- Parse the model output.
- Validate it against legal moves from the current position.
- If invalid, ask the model to pick from a provided list of legal moves.
This turns chess into a constrained selection problem rather than free-form generationmuch safer for correctness.
What This Teaches Us About Instruct Models (Beyond Chess)
Chess is just a bright spotlight. The underlying lesson applies everywhere an assistant must operate under rules:
spreadsheets, API calls, medical dosage ranges, accounting constraints, configuration files, and so on.
1) “Aligned to the user” isn’t the same as “aligned to reality”
Instruct models are often trained to be pleasant, helpful, and cooperative. That’s good. But if a system rewards
answers that feel helpful, it can also reward answers that are confidently wrong. Chess punishes that instantly.
2) Long interactions reveal compounding errors
A one-turn answer can be polished and plausible. A 40-turn chess game forces the model to stay consistent and
accurate across time. Small mistakeslike misremembering a capturecompound until the model is effectively playing
on a different board than you are.
3) The best assistants use tools, not bravado
The future of “instruct” behavior isn’t a model that pretends it can do everything internally. It’s a model that
knows when to call a tool, verify constraints, and ask for missing state. Chess is a friendly, low-stakes way to
learn that design pattern.
Where the Field Is Heading: Making LLM Chess Less Weird
Researchers are exploring multiple routes to improve chess interactions with language models:
- Better representations: focusing on current position (like FEN) rather than long PGN histories.
- Chess-specific fine-tuning: training on chess corpora to reduce illegal outputs and improve strategic consistency.
- Planning-style approaches: treating move choice as a structured planning problem rather than pure text continuation.
- Protocol-based agents: forcing models to interact via explicit actions that can be checked.
Even if a general-purpose instruct model never becomes a grandmaster, these techniques can still produce a great
chess experience: a legal, coherent opponent that explains ideas clearly, adapts to your level, and doesn’t try to
castle through a bishop like it’s phase-shifting through walls.
Conclusion: The Real Endgame
When you play chess against an LLM, you’re not just playing a gameyou’re running a diagnostic. Chess reveals how
a model handles rules, memory, long-horizon consistency, and instruction-following under pressure. The “mystery of
instruct models” isn’t that they’re secretly bad at chess; it’s that they’re optimized for a different job:
being a helpful conversational partner.
The fix isn’t to scold the model harder (“No illegal moves this time, young chatbot!”). The fix is to design the
interaction so the model can do what it does best (explain, plan, communicate) while tools or verifiers handle what
computers do best (track state, enforce rules, calculate tactics). Do that, and chess becomes an ideal demo of how
instruct models can be both delightful and reliablewithout inventing a rook on f3 because it “felt right.”
Experiences: A 500-Word Field Guide to Playing Chess vs. LLMs
If you haven’t tried it yet, here’s what the experience often feels likebased on the most common patterns people
describe when they play chess against LLMs in chat.
The opening is usually the honeymoon phase. You type “e4,” and the model replies with something reassuring like
“Great choiceclassical and principled,” then plays a recognizable response: “e5,” “c5,” maybe even “c6” with a
cheerful note about the Caro-Kann. For a few moves, it feels like you’re playing a slightly talkative club player
who also moonlights as a motivational speaker.
Then comes the first “wait… what?” moment. Maybe the model announces a move that looks plausible in notation, but
you stare at your board and realize the piece can’t do that. You point it out. The model apologizes politely,
explains it “misread the position,” and offers a correctionoften with a level of confidence that makes you wonder
if it’s bluffing or just extremely committed to the bit.
If you continue, you’ll notice a pattern: the model is amazing at chess language. It can describe threats,
talk about development, warn you about open files, and even outline a plan like “improve your worst-placed piece.”
That part can genuinely help beginners, because it narrates the game in a human way that engines don’t. You start
to treat it like a coach: “What should I be thinking about here?” and it answers with principles that make sense.
Midgame is where the instruct-model personality really shows. The model wants to be cooperative, so it keeps giving
you somethingeven when it’s uncertain. If you ask for “the best move,” it may produce a move that fits a common
pattern (fork, pin, discovered attack) without verifying that the pieces are actually arranged for that tactic.
The funniest version is when it describes a brilliant idea involving a piece you captured five turns ago. It’s not
trying to cheat; it’s continuing the story it thinks it’s in.
The most enjoyable sessions tend to be the ones where you change the rules of engagement. Instead of forcing the
model to be the referee, the scorekeeper, and the player, you give it guardrails. You feed it the position in FEN
every turn, or you ask for “three candidate moves” and then you verify legality with a board or engine. Suddenly,
the model becomes what it’s best at: a clear explainer of plans, a generator of ideas, a sparring partner for your
thinking. You’ll still catch occasional weirdness, but it feels like a quirky teammate rather than a chaotic opponent.
And if you’re building something, this experience teaches a bigger lesson: instruct models are brilliant collaborators
when you let them collaboratewhen you give them the state, let tools enforce rules, and reward them for honesty about
uncertainty. In that sense, playing chess against an LLM is less about winning and more about learning how to make
“helpful” also mean “correct.” That’s the real endgame.